Webエンジニアの職務経歴書(スキルシート)の書き方
エンジニアは職務経歴書を書いたり提出する機会が少なくない職種だ。
僕自身書き方に困ったこともあり、自分なりにテンプレートを試行錯誤したので、公開してみる。
これは実際に去年の案件探しで利用したもので、企業情報や案件の具体を中心にざっとマスクしている。
職務経歴書_テンプレート - Google ドキュメント
転職時の職務経歴書としても、フリーランスとしてのスキルシートとしても使える想定。
厳密には書き分けた方がいいかもなのだが、問題はなさそう(あまり違いをわかっていない)。
Google Documentで記述している。 - 見栄えが良い - リンクでシェアできる - PDF・Word形式でも出力できる
各章の簡単な説明と補足
1. 職務要約
開発に関わる過去の経歴をざっと書く。
僕は学生時にプログラミングを勉強してたのでそこから書いた。
2. スキル
経験が多いもの・携わりたい案件に関わるものを強調しつつ、片っ端から全部書いておく。
3. 業務外の取り組み
アウトプットにはGitHubのリンクなどを貼る。
資格・学歴は履歴書とも重複するが、アピールになりそうなものは書いておく。
4. 自己PR
アピールポイントの概要を書いておく。
詳細や根拠は他の章で書く。
5. 職務経歴
※ この章はテンプレートではかなり削っている。
全部は書けも読めもしないので、アピールになるものは多く書き、他は省略する。
適度な分量を心がける。
よくあるExcelのテンプレートはもっと複雑な構成だが、タイトル列+内容列の2列くらいが管理しやすいと思う。
総括
自分なりの職務経歴書のテンプレートを公開してみたので、活用してみて欲しい。
それぞれ自分の強みをアピールできるように構成や分量を変えると良さそう。
iPhoneのブラウザ環境で発生した「Maximum call stack size exceeded」の原因と解決
概要
Webアプリ開発中、iPhoneのブラウザ(Safari, Chrome, LIFF)でのみページが真っ白になる問題が発生。
Macのブラウザでは正常に動作しており、明確なエラーも表示されなかった。
この不具合は、JSONファイルへのデータ追加後に発生。ファイルサイズは以前より小さかったが、配列の項目数が増加していた。
原因は、JSONをESMとして import した際に、巨大な配列リテラルが生成され、iOS Safariのスタック上限を超えたことだった。
状況
- 発生環境:iPhoneのSafari / Chrome / LIFF(いずれもWebKitベース)
- 正常動作:MacのSafari / Chrome(PC環境)
- エラー:
RangeError: Maximum call stack size exceeded - トリガー:JSONファイルの項目数が約11万件を超えた
原因
JSONを以下のように静的に読み込んでいた:
import zipData from './zipcodes.json';
この import により、Viteが次のようなJSコードを生成:
export default [
{ zip: '0600000', city: '札幌市中央区' },
...
// 11万件以上
];
この配列リテラルの構文解析時、iOS Safariのスタックを消費しきり、オーバーフローを起こしていた。
背景
JavaScriptリテラルの影響
import したJSONは、バンドル時にJSのリテラル配列として埋め込まれる。
構文の「深さ」ではなく、「長さ」(項目数)が多い場合でもスタックを消費する。
iOS Safariの制限
iOSのWebKitエンジンはスタック上限が低く、構文ノード数が多いコードでクラッシュしやすい。
PCでは問題ないコードでも、iPhoneではクラッシュする場合がある。
対処法
JSONを静的に import せず、fetch() + JSON.parse() による動的読み込みに変更:
useEffect(() => {
fetch('/data/zipcodes.json')
.then(res => res.json())
.then(setZipData);
}, []);
JSONファイルは public/ に移動し、JSバンドルから除外。
構文としてパースされないため、iPhoneでも安定して動作するようになった。
教訓
これまでの記事まとめ
4年弱書いてきたブログですが、今回で定期投稿は終了します。
これまでの記事を振り返ってみたいと思います。
最初の1年は週1本、以降は2週に1本、合計127本書いたようです。
書評やイベント参加の記事などもありましたが、多くは開発のログでした。
TODOリスト
最初の開発はTODOリストでした。
技術スタックはVue3, TypeScript, Go言語, Bulmaで、どれも業務・プライベート含め初めての利用でした。
Vue2は経験があったものの、Vue3のComposition APIは初めてで苦戦しました。
しかしなんと言っても初めてのGo言語が最も印象的です。
業務で使っているPHPとは全然違っていて、やはり型の強力さを実感しました。
その後業務ではPHPDoc, PHPStanを利用して型を活かした開発ができるように進めたりもしました。
今の所この時しか使えていないので、今後また機会を作りたいです。
またViteを利用したのですが、これも動作が速くて驚きました。
Bulmaは手軽で軽量で、までもお気に入りです。
将棋盤
2つ目の開発は将棋盤でした。
趣味の1つが将棋ということもあり、それに関連した開発をしてみたかったというのが契機でした。
この時もVue3を使った開発でした。
TODOリストの時よりも複雑なロジックを書いたため、TypeScriptやComposition APIの記述に苦戦しました。
タイピングゲーム
3つ目の開発はタイピングゲームでした。
この時もVue3を使った開発でした。
「ん」や「っ」に対応するのがかなり大変でした...。
この時のコードはかなりひどかったのと、TypeScriptをもっと使いこなせればもっと楽に書けただろうにと思います。
プロフィールページ
4つ目の開発はプロフィールページです。
https://nek0meshi.github.io/profile/
このページは特に人に見てもらいたいようないい出来でした。
初めてデザインに挑戦しました。Figmaを使ってみたり、色々なページを見て参考にしたりしました。
基本的には自力で進めましたが、Web制作の仕事をしている身内にアドバイスしてもらったこともとても勉強になりました。
HTML/CSS の力もこの時とてもつきました。
Nuxt.jsやTailwindCSSを利用した開発でした。
機械学習入門
5つ目の開発では機械学習に入門しました。
Python・jupyter notebookを使った開発でした。
書籍を参考にしてPerceptronを作りました。
Web開発とは遠い分野でしたが、とても楽しい経験にもなりました。
テトリス
6つ目の開発はテトリスです。
この時が初めてのReactを使った開発でした。
この経験を元に業務のプロダクトにReactを導入したのでとても有意義な挑戦にもなりました。
機能が足りてはいないものの、いい感じに動くものが作れて満足しています。
自作ブログ
7つ目の開発は自作ブログです。
この時はReact・Next.jsを使いました。
仕組みとしてはほぼ出来上がったものの、移行に至っていないのは残念です。
やはりはてなブログが便利ですね。
移行したいと思えるためには、自分に合ったもうひと工夫が必要かもしれません。
あとがき
振り返ってみて、こんなにたくさんの記事・たくさんの開発をしたことに自分自身驚きました。
またその成果をかなり業務にも取り入れることができたことは予想以上で、本当に良かったです。
今後も少しずつ業務外の勉強や開発を続けていきたいと思います。
デスク紹介
最近キーボードを新調したりしていたので、初めてですがデスク紹介をしてみようと思います。
私はあまりガジェット類に通じていない方なのですが、その分比較的王道なラインナップになっているかなと思います。
誰かの参考になれば嬉しいです。
概要
下記のような構成になっています。
| PC | Macbook Pro 16インチ 2021 |
| キーボード | HHKB Professional HYBRID Type-S 英語配列 墨 |
| トラックパッド | Apple Magic Trackpad |
| モニター | IO DATA 4K Type-C 27inch |
| PCスタンド | BoYata PCスタンド |
| デスクマット | サンワダイレクト デスクマット フェルト 60×30cm |

Macbook Pro 16インチ 2021
会社支給のPCです。
スマレジでは、エンジニアには同等のスペックのPCが貸し出されます。
通常の開発をする範囲では、性能は申し分ないと思ってます。
数年ごとに交換してもらえます。
HHKB Professional HYBRID Type-S 英語配列 墨
言わずと知れたHHKBです。

つい最近購入したのですが、とてもお気に入りです。
最近までは、60%・メカニカル赤・日本語配列のゲーミングキーボードを使っていましたが、打鍵音の大きさやキーマップに関する問題がありました。
エンジニアのユーザーがとても多い安心感と、レンタルした時の音の静かさや打鍵感の良さ、十分なキーマップ性能を確かめた上で購入しました。
買ったばかりと言うこともありますが、本当に「タイピングが楽しい」という感覚を味わえています。
下記のサイトでレンタルをしました。
事前に十分試して安心の上購入ができたことはもちろん、期間限定のようですがクーポンも付いておりレンタルしない場合と変わらない金額で購入できました。
宅配便でやり取りするだけでとても簡単なので、おすすめです。
Apple Magic Trackpad
以前まではトラックボールを使っていたのですが、下記の問題がありました。
- マウスホイールがおかしくなってしまった
- 私の環境ではボタン割り当てがうまく動作しなかった
- 右手を定位置に置かないと使えないのがたまに不便
- 持ち運びに嵩張る
結局一番良いかと思いトラックパッドを購入しました。
上記の問題が解決したので購入してよかったです。
ただトラックボールに比べると手首の負担が大きく、慣れるのか心配しています。
IO DATA 4K Type-C 27inch
 EX-CU271AB-F")
【自作ブログ #16】デザイン調整
自作ブログを作っています。
技術スタック
- TypeScript
- React
- Next.js
- Styled Components
- GitHub Pages
今回からデザイン調整を行います。
まずはResponsive対応を行います。
Responsive対応
Responsive対応、すなわち表示端末の画面サイズに応じて表示を切り替える対応を行います。
今回は、PC画面・iPad画面・スマホ画面を目安にした3つのサイズに対応します。
現在は幅が飛び出すような表示になってしまっています。


下記のように対応しました。
PC画面


iPad画面

スマホ画面


コード
適用したのは下記のコードです。
const GAP = '50px' const SIDE_MENU_FULL_SCREEN_WIDTH = '240px' const SIDE_MENU_TABLET_WIDTH = '180px' const StyledContainer = styled(Container)` display: flex; justify-content: space-between; flex-shrink: 0; gap: 50px; gap: ${GAP}; padding: 0 ${VERTICAL_PADDING}; ` const StyledMain = styled.main` width: calc(100% - ${GAP} - ${SIDE_MENU_FULL_SCREEN_WIDTH}); @media (max-width: ${TABLET_MAX_WIDTH}) { width: calc(100% - ${GAP} - ${SIDE_MENU_TABLET_WIDTH}); } @media (max-width: ${MOBILE_MAX_WIDTH}) { width: 100%; } ` const StyledSideMenu = styled(SideMenu)` width: 240px; @media (max-width: ${TABLET_MAX_WIDTH}) { width: ${SIDE_MENU_TABLET_WIDTH}; } @media (max-width: ${MOBILE_MAX_WIDTH}) { width: 100%; } ` const MainContainer = ({ children, matters }: Props) => { return ( <StyledContainer> <StyledMain>{children}</StyledMain> <StyledSideMenu matters={matters} /> </StyledContainer> ) }
Pull Request
https://github.com/nek0meshi/blog/pull/21
あとがき
次回はその他のデザイン調整を行なっていきます。
HHKBのキーボードをレンタルしてみました。
機種はHHKB Professional
HYBRID Type-Sです。
打鍵感が最高に良い上、かなり静かで周りに迷惑をかけづらくいい感じです。
下記のサイトでレンタルしました。
https://geo-arekore.jp/product/pfu-pd-kb800bs.
購入を検討中です。
【コンポーネント #4】Buttonコンポーネントを作る
引き続きComponentライブラリを作っていきます。
技術スタックは下記の通りです。
- TypeScript
- React
- Bulma
- vite
- Bulma
- Storybook
- ESLint
- Prettier
- asdf
Buttonコンポーネントを作る
HTMLの <button /> に対してBulmaでデザイン装飾をしたり、イベントハンドリングを簡易に行えるようにします。
まずは装飾のための型を定義します。
それぞれ、Bulmaでボタンの色・サイズを指定する時のclass名と一致させています。
type ButtonColor = 'is-primary' | 'is-warning' | 'is-danger' type ButtonSize = 'is-small' | 'is-normal' | 'is-medium' | 'is-large'
<button /> のtype(button/submit)を指定するための型も定義します。
type ButtonType = 'button' | 'submit'
Buttonコンポーネントの引数のinterfaceを定義します。
interface Props { children: ReactNode className?: string color?: ButtonColor isOutlined?: boolean onClick: () => void size?: ButtonSize type?: ButtonType }
先ほど定義した型を利用するcolor/size/typeの他に下記の引数を用意しました。
- children: Buttonコンポーネントの内部の表示を渡す
- className: 親から渡すクラス名
- isOutlined: 枠表示の装飾を適用するかどうかのクラス
- onClicked: クリックイベントのハンドラ
最後にButtonコンポーネント本体を作成します。
前回作成したuseClassName hookを利用し、デザイン装飾に関する引数を適宜加工しつつ_classNameとしてまとめます。
export const Button = ({ children, className, color, isOutlined = false, onClick, size, type = 'button', ...props }: Props) => { const _className = useClassName( className, 'button', color, isOutlined && 'is-outlined', size, ) return ( <button className={_className} onClick={onClick} type={type} {...props}> {children} </button> ) }
storyの作成
動作を確認するためにStorybookのstoryを作ってみます。
今回は、Storybook導入時に自動で作成されるstoryを元に簡易に作ってみました。
(Button.stories.ts) import type { Meta, StoryObj } from '@storybook/react' import { Button } from './Button' const meta = { title: 'Components/Button', component: Button, parameters: { layout: 'centered', }, tags: ['autodocs'], } satisfies Meta<typeof Button> export default meta type Story = StoryObj<typeof meta> export const Default: Story = { args: { children: 'Button', }, }
動作確認をしてみます。

Storybookが引数を認識して自動で表示切り替えの仕組みを作ってくれています。 無事にBulmaのクラスを適用できているようです。

あとがき
最近は機能開発のかたわらで業務のアジャイル化に取り組んでいます。
また始まったばかりですが、効果が出そうな感触があって楽しみです。
トラックボールを使っていたのですが、少々の不都合がありトラックパッドを買ってみました。
こちらも今後の活躍が楽しみです。
【コンポーネント #3】CIの導入・ClassName管理のHook化
引き続きComponentライブラリを作っていきます。
技術スタックは下記の通りです。
- TypeScript
- React
- Bulma
- vite
- Bulma
- Storybook
- ESLint
- Prettier
- asdf
Prettier・CIの導入
プロジェクトを作ったらとりあえずPrettierを入れておきます。
npm i -D prettier
prettierの設定ファイルを導入します。
semi: false singleQuote: true
package.json に登録します。
"scripts": { "prettier": "prettier -c .", "lint": "npm run eslint && npm run prettier", }
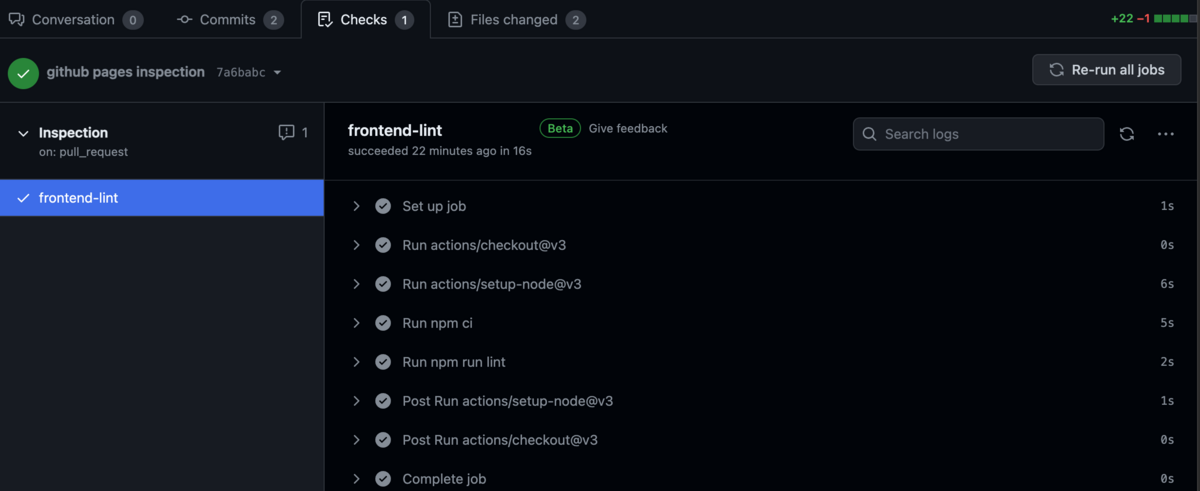
CIで実行されるようにします。
name: Inspection on: pull_request: branches: - master jobs: frontend-lint: runs-on: ubuntu-latest steps: - uses: actions/checkout@v3 - uses: actions/setup-node@v3 with: node-version-file: '.tool-versions' cache: 'npm' cache-dependency-path: 'package-lock.json' - run: npm ci - run: npm run lint
Pushすると、無事に実行されました。
Pull Request
ClassName 管理用のHookの追加
React Componentを作成するとき、必ずclass要素(React上ではclassName)の管理が必要になります。
便利なライブラリがあるので、まずは導入します。
npm i --save clsx
Hookにまとめて抽象化します。
import { useMemo } from 'react' import clsx from 'clsx/lite' export const useClassName = ( ...classNames: (string | undefined | false)[] ): string => { return useMemo(() => clsx(...classNames), [classNames]) }
下記のように利用できます。
export const Button = ({ children, className, isOutlined = false, onClick, size, }: Props) => { const _className = useClassName(className, 'button', isOutlined && 'is-outlined') return ( <button className={_className} onClick={onClick} > {children} </button> ) }
Pull Request
https://github.com/nek0meshi/components/pull/9
あとがき
業務の開発ではReact・jQuery・AngularJSを交互に触るので不思議な気持ちです。
先日は推しの子展を観にいきました。大好きなアニメ・漫画なので、とても感激しました。